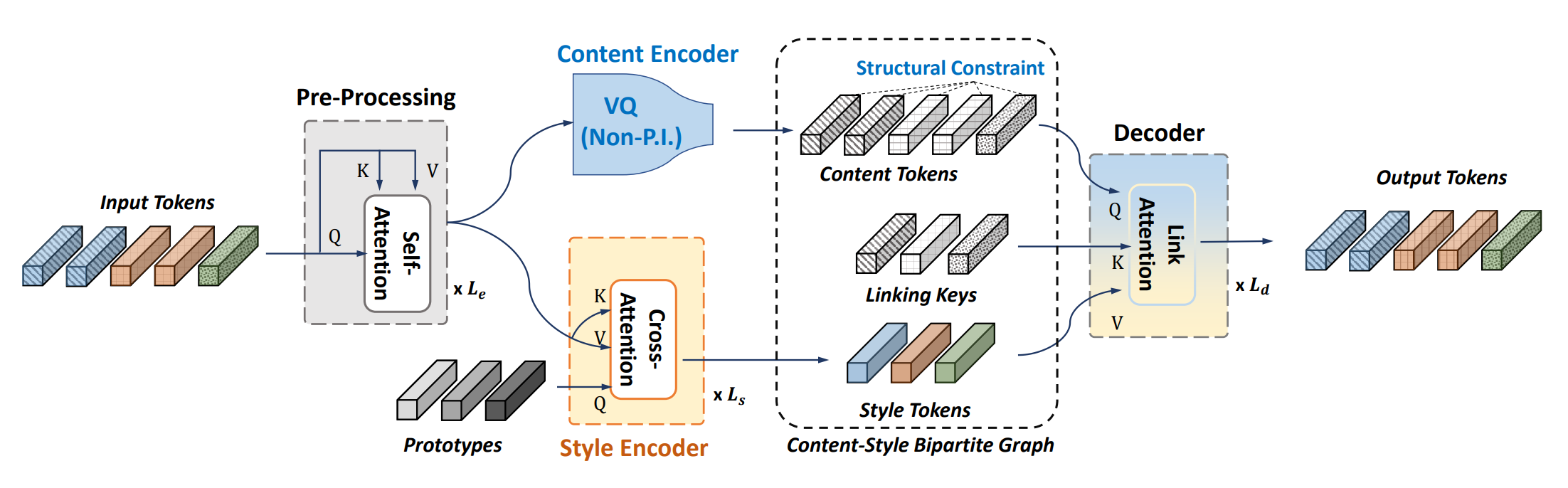
Method
The framework is called "Retriever" because of its dual-retrieval operations: the cross-attention module retrieves style for content-style separation, and the link attention module retrieves content-specific style for data reconstruction.
In this paper, style is defined as permutation invariant (P.I.) information. The first retrieval, serving as style encoder, is permutation invariant to the input tokens, thus blocking any non-P.I. information to pass through it. To prevent style information from leaking into the content representation, we use VQ information bottleneck in the content branch.