
PHASEN: A Phase-and-Harmonics-Aware Speech Enhancement Network.
Published in The Thirty-Fourth AAAI Conference on Artificial Intelligence, 2020
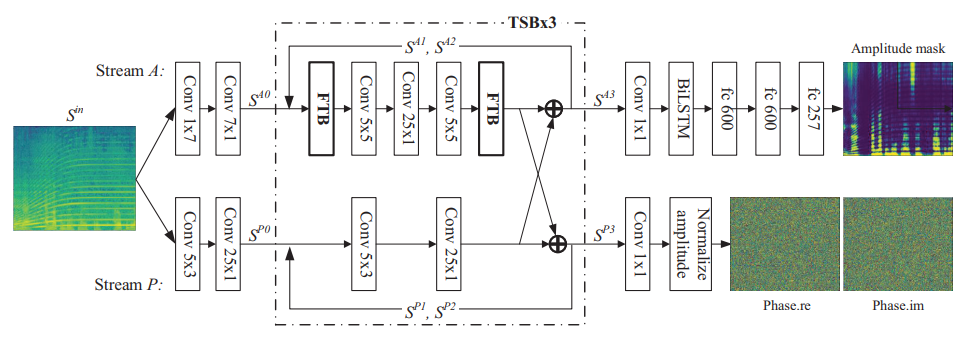
Time-frequency (T-F) domain masking is a mainstream approach for single-channel speech enhancement. Recently, focuses have been put to phase prediction in addition to amplitude prediction. In this paper, we propose a phase-and-harmonics-aware deep neural network (DNN), named PHASEN, for this task. Unlike previous methods which directly use a complex ideal ratio mask to supervise the DNN learning, we design a two-stream network, where amplitude stream and phase stream are dedicated to amplitude and phase prediction. We discover that the two streams should communicate with each other, and this is crucial to phase prediction. In addition, we propose frequency transformation blocks to catch long-range correlations along the frequency axis. Visualization shows that the learned transformation matrix implicitly captures the harmonic correlation, which has been proven to be helpful for T-F spectrogram reconstruction. With these two innovations, PHASEN acquires the ability to handle detailed phase patterns and to utilize harmonic patterns, getting 1.76dB SDR improvement on AVSpeech + AudioSet dataset. It also achieves significant gains over Google’s network on this dataset. On Voice Bank + DEMAND dataset, PHASEN outperforms previous methods by a large margin on four metrics.
Cite
@inproceedings{yin2020phasen,
title={Phasen: A phase-and-harmonics-aware speech enhancement network},
author={Yin, Dacheng and Luo, Chong and Xiong, Zhiwei and Zeng, Wenjun},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={34},
number={05},
pages={9458--9465},
year={2020}
}