
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Published in InterSpeech, 2021
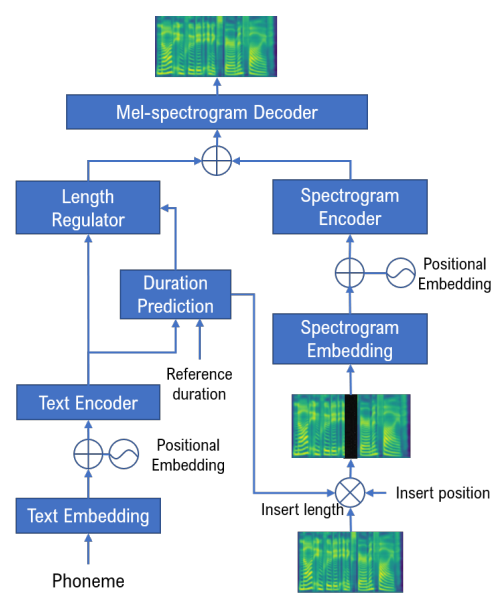
Given a piece of speech and its transcript text, text-based speech editing aims to generate speech that can be seamlessly inserted into the given speech by editing the transcript. Existing methods adopt a two-stage approach: synthesize the input text using a generic text-to-speech (TTS) engine and then transform the voice to the desired voice using voice conversion (VC). A major problem of this framework is that VC is a challenging problem which usually needs a moderate amount of parallel training data to work satisfactorily. In this paper, we propose a one-stage context-aware framework to generate natural and coherent target speech without any training data of the target speaker. In particular, we manage to perform accurate zero-shot duration prediction for the inserted text. The predicted duration is used to regulate both text embedding and speech embedding. Then, based on the aligned cross-modality input, we directly generate the mel-spectrogram of the edited speech with a transformer-based decoder. Subjective listening tests show that despite the lack of training data for the speaker, our method has achieved satisfactory results. It outperforms a recent zero-shot TTS engine by a large margin.
Cite
@article{tang2021zero,
title={Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration},
author={Tang, Chuanxin and Luo, Chong and Zhao, Zhiyuan and Yin, Dacheng and Zhao, Yucheng and Zeng, Wenjun},
journal={arXiv preprint arXiv:2109.05426},
year={2021}
}